Introduction
Large Language Models (LLMs) have emerged as a promising paradigm for time series analytics, leveraging their massive parameters and the shared sequential nature of textual and time series data. However, a cross-modality gap exists between time series and textual data, as LLMs are pre-trained on textual corpora and are not inherently optimized for time series. In this tutorial, we provide an up-to-date overview of LLM-based cross-modal time series analytics. We introduce a taxonomy that classifies existing approaches into three groups based on cross-modal modeling strategies, e.g., conversion, alignment, and fusion, and then discuss their applications across a range of downstream tasks. In addition, we summarize several open challenges. This tutorial aims to expand the practical application of LLMs in solving real-world problems in cross-modal time series analytics while balancing effectiveness and efficiency. Participants will gain a thorough understanding of current advancements, methodologies, and future research directions in cross-modal time series analytics. Our tutorial slides can be found here.
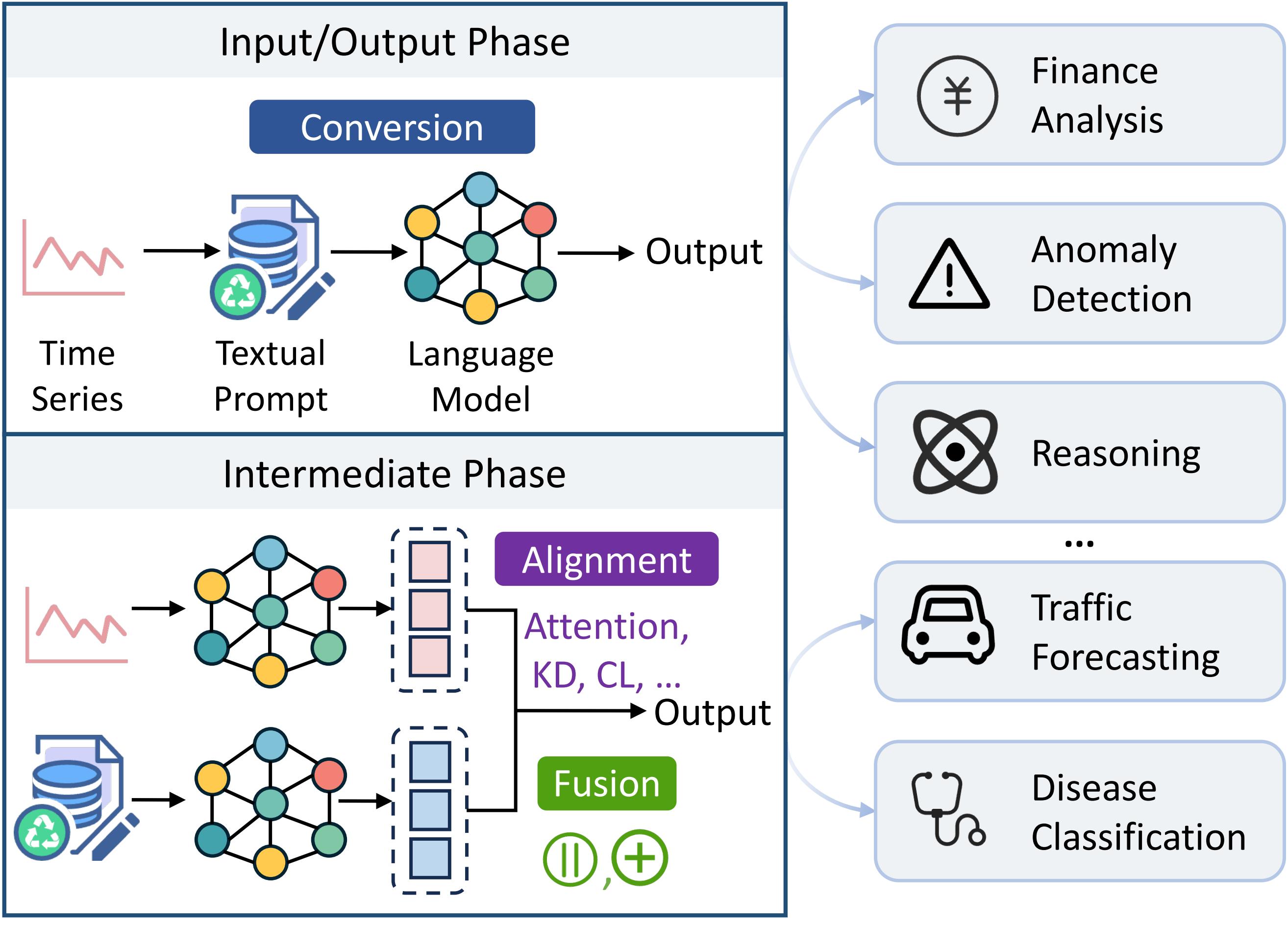
Intended Audience
This tutorial is designed for a broad audience of researchers who are interested in time series analytics, LLMs, and multimodal learning.
We assume participants have a basic understanding of machine learning and sequential data modeling, making the content accessible to professionals and students alike. Attendees will gain a comprehensive understanding of the methodologies and challenges in cross-modal time series analytics. They will also become familiar with emerging applications across domains, and will learn how to integrate textual knowledge into time series tasks using LLMs.
Tutorial Outline
| Time | Session | Presenter |
|---|---|---|
| 11:00-11:15 | Welcome & Introduction | Chenxi Liu |
| 11:15-11:30 | LLMs for TS Outlier Detection | Hao Miao |
| 11:30-11:50 | Spatio-Temporal LLMs | Ziyue Li |
| 11:50-12:15 | Cross-Modal Modeling | Chenxi Liu |
| 12:15-12:25 | Future Directions, Q&A | All |
Presenters

Chenxi Liu
Nanyang Technological University

Hao Miao
The Hong Kong Polytechnic University

Cheng Long
Nanyang Technological University

Yan Zhao
University of Electronic Science and Technology of China

Ziyue Li
Technical University of Munich

Panos Kalnis
King Abdullah University of Science and Technology
Web Administrator
Jinghan Zhang, Zhengzhou University, China